



1. Présentation de l'offre logicielle d'Intel▲
Le premier message d'Intel est que la présence d'architectures multi-cœurs est désormais une réalité et va aller en s'accroissant. Ne serait-ce que parce que l'on traite un volume de données toujours plus important.
De plus, alors que l'on se place généralement dans un contexte symétrique, où tous les cœurs sont équivalents, on va évoluer vers une situation plus hybride, où il y aura des cœurs plus ou moins haut de gamme qui cohabiteront dans une même machine (par exemple, dans un premier temps, les cœurs du processeur central et ceux d'une carte graphique, et dans le futur des cœurs supplémentaires plus polyvalents, avec des architectures comme Larabee).
Or le développement parallèle apporte ses nouveaux challenges et est intrinsèquement plus complexe que le développement sériel, en plus d'être assez peu maîtrisé par les développeurs actuels. Intel propose donc des outils pour aider à gérer cette complexité.
1-A. Évolutions▲
1-A-1. Parallel Studio▲
L'offre Intel Parallel Studio, sortie depuis près d'un an, s'intègre dans Microsoft Visual Studio 2005 et 2008. Intel a annoncé qu'une nouvelle version va naturellement être développée pour prendre en compte Visual Studio 2010. Cette version sera bientôt en programme bêta, avec une sortie prévue vers novembre. À part l'intégration à Visual Studio, la seule fonctionnalité annoncée de cette version est l'arrivée tant attendue de Parallel Advisor. Ce produit doit permettre de prototyper rapidement à quoi pourrait ressembler le passage en parallèle d'un bout de code existant, quelles améliorations en attendre, quelles difficultés seront rencontrées, afin de permettre de concentrer l'effort de développement là où il a toutes les chances d'être rentable.
Par ailleurs, Intel a aussi annoncé qu'une partie de cette suite logicielle devrait sous peu être disponible sous Linux, afin de satisfaire une plus large base d'utilisateurs.
1-A-2. TBB▲
TBB, Thread Building Blocks, est la bibliothèque libre et portable créée par Intel pour mettre en place le parallélisme dans un programme, avec des opérations de création de tâches, des structures de données thread safe, des primitives de synchronisation... Cette bibliothèque, actuellement dans sa version 2, doit basculer dans sa version 3 la semaine suivant la conférence. La principale nouveauté est que, sous Windows, elle sera implémentée à l'aide du concurrency runtime mis à disposition par Microsoft. Cette implémentation va permettre de bénéficier des améliorations de performance liées à ce runtime (voir la section sur le concurrency runtime), mais surtout les programmes développés avec TBB collaboreront plus aisément avec des programmes développés par d'autres technologies basées elles aussi sur ce runtime.
Par exemple, on sait que, quel que soit le nombre de tâches actives, il vaut mieux que le nombre de threads actifs soit à peu près égal au nombre de cœurs disponibles. Si, par exemple sur une architecture quadri-cœurs, deux application tournent en même temps sans se préoccuper l'une de l'autre, elles vont avoir chacune tendance à créer quatre threads, ce qui fait que l'OS devra en gérer huit en tout. Le concurrency runtime va permettre à ces applications de collaborer pour éviter ce gâchis de ressources.
Une autre avancée est l'utilisation de C++0x. TBB est une bibliothèque relativement ancienne, ce qui apporte des avantages en terme de maturité, mais dans sa première version, elle ne permettait bien évidemment pas de tirer parti des nouveautés du C++0x qui était encore à l'état embryonnaire à l'époque, et en particulier des lambdas. Or, ces lambdas permettent une écriture bien plus aisée du code parallèle, en particulier en évitant de rompre le flot de lecture du code. Une première étape vers l'utilisation de ces nouveautés avait été apportée par TBB version 2 et cette notation est désormais élargie à l'ensemble du code avec TBB version 3. Par exemple, ce qui en V1 devait s'écrire :
struct ApplyScalarVector
{
ApplyScalarVector(Vector &a, Matrix const &b, Matrix const &c) :
myA(a), myB(b), myC(c)
{}
void operator()(int i)
{
myA(i) = ProduitScalaire(myB(i,12), myC(42, i));
}
Vector &myA;
Matrix const &myB;
Matrix const &myC;
};
void f()
{
// Initialisation de a, b, c
parallel_for(0, a.size(), ApplyScalarVector(a, b, c));
}peut désormais s'écrire (avec un compilateur comprenant les lambdas, mais les dernières versions de Intel C++ compiler, Microsoft Visual C++ et gcc le font) :
Void f()
{
// Initialisation de a, b, c
parallel_for(0, a.size(), [&](size_t i)
{
a(i) = ProduitScalaire(b(i, 12), c(42, i));
}
}1-A-3. Divers▲
Une nouvelle génération des compilateurs et bibliothèques Intel pour Linux, Windows et Mac Os X est aussi prévue, mais il n'a pas été donné plus de détails sur le contenu.
1-B. Nouveaux produits▲
1-B-1. Ct▲
La technologie Ct, dont Intel parle depuis longtemps maintenant, devrait être mise sur le marché cette année. Cette technologie se présente sous la forme d'une bibliothèque templates destinée à paralléliser du code dans le domaine particulier du parallélisme de données. Contrairement à TBB, le but n'est pas ici de fournir des outils pour que le développeur mette en place du parallélisme, mais plutôt de fournir une bibliothèque de haut niveau que l'utilisateur manipule sans faire particulièrement attention, mais qui parallélise tout seul. Voici un exemple de code Ct :
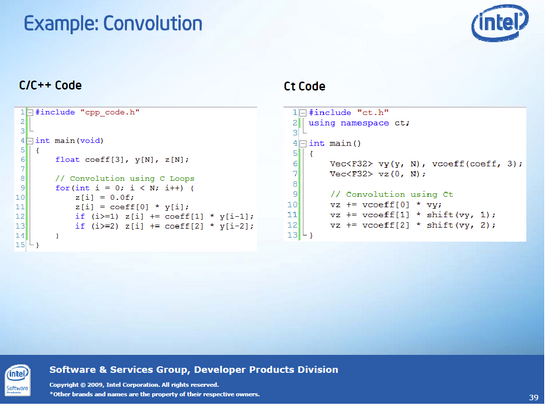
Afin d'y parvenir de manière efficace, des restrictions sont apportées sur les données gérées par cette bibliothèque, par rapport à des données classiques C++. En particulier, le système est susceptible de bouger les données en mémoire. Ce qui est vraiment innovant avec cette technologie et qui la démarque des autres bibliothèques de templates disponibles pour ce genre d'opérations, c'est qu'elle ne génère pas directement du code, mais un code intermédiaire à destination d'une compilateur just-in-time.
À première vue, on pourrait s'interroger sur l'intérêt de cette compilation lors de l'exécution du code, et non pas au préalable, comme on en a l'habitude en C++. En fait, cet intérêt est double :
- au moment de l'exécution, on sait sur quelle machine on se trouve et donc la compilation peut à ce moment là tirer parti de toutes les ressources présentes, comme des co-processeurs, des cartes graphiques haut de gamme... Ainsi, le code qui s'exécutera pourra automatiquement, par exemple, être parallélisé et exploiter simultanément sur deux cœurs classiques en SSE, une carte graphique et un Larrabee ;
- il existe une certaine catégorie de code de calcul où les calculs sont connus à la compilation. Mais toute une série de problèmes demandent une configurabilité, une flexibilité à l'exécution. Avec une architecture classique, cette flexibilité a un coût. Là, comme on passe par du JIT, ce code est compilé en cours d'exécution et on élimine ce coût
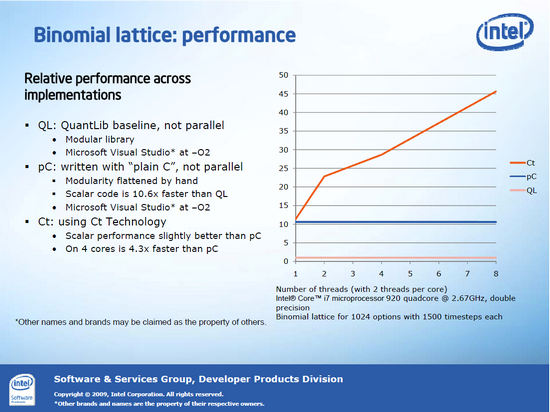
Voici un bench réalisé par Intel montrant les performances de Ct par rapport à deux applications réalisant une même tâche (l'une flexible, l'autre non) :
Intel a racheté la société RapidMind, connue en particulier dans le monde du jeu pour exploiter les architecture multi-cœurs et les GPU. Ce rachat introduit des changements importants dans la syntaxe utilisée jusqu'à présent et une bêta du produit devrait se stabiliser en automne pour une sortie en 2011. Voici une petite comparaison des deux syntaxes utilisées :

1-B-2. Cilk▲
L'idée derrière Cilk, technologie du MIT rachetée par Intel, part du fait qu'un compilateur qui aurait connaissance de primitives de base du parallélisme pourrait en tirer avantage, par rapport aux solutions actuelles uniquement sous forme de bibliothèque. Cilk est un jeu d'instructions parallèle minimaliste, destiné à faire du parallélisme de tâches, et géré directement dans le compilateur.


J'avoue avoir été peu convaincu par la présentation de ce produit. Il est à mon avis trop simpliste pour pouvoir être mis en œuvre dans des cas réels. Le fait que les primitives soient comprises par le compilateur peut être un avantage, mais cet avantage serait absolument identique si ces primitives étaient utilisées en interne par des bibliothèques comme TBB et non exposées à l'utilisateur.
Une autre présentation qui m'a été envoyée après la conférence montre qu'en réalité, en plus des primitives mentionnées, Cilk serait fourni avec une bibliothèque, ayant a priori comme principal objectif de collecter les données traitées séparément dans chaque itération d'une boucle cilk_for, ce qui permet déjà de faire plus de choses.
Un avantage annoncé de cette technologie est que les modifications à apporter au code sont vraiment réduites (on pourrait très aisément mettre en place un jeu de macros ou un flag du compilateur, permettant d'activer/désactiver le parallélisme selon le mode de compilation). L'intérêt principal étant de pouvoir aisément déboguer la version non parallélisée de l'algorithme, là ou d'autres solutions ont plus de mal à être "transparentes" pendant cette première phase de mise au point.
1-B-3. SIMD pragmas, array notation▲
Il y a eu peu d'informations données sur ces technologies, prévues pour 2010. Voir l'interview de James Reinders pour un exemple de l'array notation.
2. Présentation de Visual Studio 2010▲
Steve Teixeira, le responsable des outils de développement parallèle chez Microsoft, a présenté les nouvelles fonctionnalités présentes dans la très récente version de Visual Studio. Ces nouveautés s'articulent autour de trois axes : les moteurs, les APIs et les outils.
2-A. Le concurrency runtime▲
Ce moteur d'exécution en parallèle est une nouveauté de Visual Studio 2010. Il est utilisé à la fois par les API C++ et .Net pour gérer l'exécution parallèle de code. Là où l'OS ne nous fournissait que la notion de thread, il nous propose de manipuler des tâches, qui a première vue peuvent ressembler à des threads, mais sont en fait des objets bien plus légers et qui peuvent au final être distribués sur divers threads système.
L'objectif est de minimiser les surcoûts, afin d'éviter que le temps de création de tâches ou de synchronisation entre tâches ne vienne faire perdre ce qu'on a pu gagner en parallélisant. Une des contraintes est ainsi d'éviter au maximum de faire des appels au noyau du système d'exploitation, car ces appels sont coûteux. Cette petite vidéo illustre la notion de task stealing ayant pour but de concilier deux notions : exécuter du travail sur un seul processeur dans la mesure du possible, afin en particulier d'optimiser le cache et ne pas laisser un processeur inactif.
Ce concurrency runtime est le cœur de la nouvelle architecture multi-cœurs de Microsoft et, comme indiqué précédemment, Intel a décidé de se baser dessus pour implémenter TBB sous Windows (bien qu'Intel utilise son propre scheduler).
2-B. Les API : TPL et PPL, PLinq▲
Afin de tirer parti du concurrency runtime, des API de plus haut niveau et permettant d'exprimer des tâches simplement devaient être mise en place. C'est chose faite avec PPL, qui est une API C++ et TPL, qui est une API managée. Ces deux API recouvrent à peu près les mêmes notions, mais sont écrites en utilisant les spécificités de chaque langage. Par exemple, cette image illustre les API de lancement de threads dans ces deux langages :

PPL est assez inspirée des TBB d'Intel. En particulier toutes les collections fonctionnant de manière concurrente (concurrent_queue, concurrent_vector...) sont reprises à l'identique. Pour ce qui est de la partie lancement de tâches ou de la partie synchronisation, des différences d'écriture subsistent, mais les concepts mis en place sont identiques.
On peut noter en première impression une certaine pauvreté par rapport à TBB, mais des exemples viennent compléter un peu ça, et la couverture des deux API devient alors plus semblable.
PPL propose aussi une programmation par agents, qui n'a pas d'équivalent dans TBB et peut être appropriée pour coordonner à haut niveau un programme parallèle.
Enfin, on peut mentionner Plinq,une version parallèle de Linq, qui parallélise une requête formulée dans une syntaxe proche de SQL automatiquement et donc sans risque d'erreur ni de race condition. Le point qui me laisse un peu sur ma faim avec cette bibliothèque, c'est que toutes les démonstrations que j'ai pu voir de cette technologie se basaient sur le fait que l'ensemble des données sur lesquelles travailler étaient montées en mémoire sur le poste local.
Or, classiquement, ce genre de requête s'adresse à un serveur de base de données, et les performances s'obtiennent en parallélisant ce dernier, et en optimisant la bande passante entre serveur et client, mais pas vraiment en parallélisant quoi que ce soit sur le poste client. Utiliser cette technologie reviendrait donc à récupérer par réseau 1 Go de données, puis à optimiser à fond le calcul en local de la requête, alors qu'un fonctionnement classique ferait effectuer cette requête par le serveur qui ne nous retournerait alors qu'1 ko correspondant à ses résultats...
2-C. Les outils▲
Puisque l'objectif est que le développeur s'éloigne de la notion OS de thread, pour utiliser la notion, plus proche du code, de tâche, il aurait été dommage qu'au niveau du débogueur, il soit obligé de revenir aux threads sous-jacents aux tâches. Il peut le faire s'il le souhaite, mais le débogueur a été modifié pour présenter la notions de tâche à l'utilisateur.
En cours d'exécution, sur un point d'arrêt, on peut ainsi examiner la liste des tâches en cours, savoir lesquelles sont actives, lesquelles sont en attente de lancement, lesquelles sont en attente sur un mécanisme de synchronisation, et même lesquelles sont en deadlock. Il est bien entendu possible d'examiner la pile d'appels associée à chaque tâche.
Plus impressionnant, il est possible d'afficher ces tâches sous forme d'arbre indiquant qui a lancé qui, et offrant une vue synthétique de ce qui est en train de se passer. Cette petite vidéo devrait vous donner un avant goût de cette fonctionnalité :
Comme de la programmation au niveau des tâches incite à créer un grand nombre de tâches (contrairement à la programmation au niveau des threads), on peut se demander si ce type de vue restera utilisable dans un véritable programme. Il y a la possibilité de la filtrer pour n'afficher que les tâches qui nous intéressent à un instant particulier, espérons que ça suffise.
Pour ce qui est de l'analyse de performance, un autre outil permet, un peu comme le gestionnaire de tâches de Windows, d'obtenir une idée de l'activité des processeurs pendant l'exécution d'un programme, mais bien entendu avec des informations supplémentaires. Je retiens en particulier la possibilité d'ajouter des marqueurs indiquant le début d'une action et permettant de bien cibler le bout de code que l'on est en train d'analyser.
On peut aussi afficher l'état d'activité des différents threads au cours de l'exécution, ou encore renverser l'affichage, et montrer les différents cœurs et quel thread était actif sur quel cœur à chaque instant (trop de basculement étant un signe que le système ne se comporte pas de manière optimale, il y a probablement trop de threads actifs simultanément).
Finalement, il manque quand même une catégorie d'outils pour compléter notre boîte à outils : des outils permettant de vérifier que le code écrit est correct en terme de parallélisme, en vérifiant par exemple qu'il n'y a pas eu de race condition lors de l'exécution d'un code ou, bien plus utile, que le code est écrit de telle façon que, quelle que soit la manière à chaque fois différente dont il va s'exécuter, il n'y a pas de race condition potentielle. C'est ce genre de vérifications que fait Parallel Inspector d'Intel Parallel Studio. Peut-être qu'une prochaine version des outils Microsoft rattrapera ce retard ?
3. Présentations d'utilisateurs▲
Plusieurs présentions d'utilisateurs des outils Intel venaient compléter cette conférence. Nous avons ainsi eu droit à la présentation d'un centre de calcul réalisé à partir de 3280 nœuds, reliés par Infiniband.
Deux présentations sont venues nous parler du monde de l'embarqué et de l'informatique mobile. Ce n'est pas trop mon domaine et j'ai donc assez peu suivi. Le message que voulait faire passer Intel, je pense, est que dans ces domaines aussi, les architectures multi-cœurs allaient faire leur apparition, avec des problématiques légèrement différentes (par exemple, j'ai deux cœurs, un actif, l'autre en veille et une nouvelle tâche se présente, vaut-il mieux réveiller le second cœur ou attendre et économiser de la batterie ?).
Deux autres retours d'expériences correspondaient plus au thème de la conférence (voir les deux paragraphes ci-dessous).
3-A. Outils utilisés pour les calculs HPC à Aachen▲
Une présentation était elle aussi un peu centrée sur le domaine des centres de calculs haute performance, où le responsable de l'équipe en question de l'université d'Aachen nous a indiqué comment ils mettaient en œuvre le parallélisme massif. Dans ce genre d'activité scientifique, écrire un logiciel de simulation fait partie d'un travail de recherche socialement accepté. Par contre, optimiser ce logiciel pour qu'il tourne de manière performante et parallèle n'est pas dans les usages. L'objectif est donc de fournir des outils qui permettent aux scientifiques d'avoir des résultats corrects la plupart du temps et éventuellement d'intervenir de manière ponctuelle si le besoin s'en fait sentir.
Dans ce cadre, le choix de bons outils est crucial et voici quelques remarques en vrac sur les outils qu'ils utilisent :
- des profilers classiques (Visual studio, gprof) qui travaillent au niveau de la fonction ne sont généralement pas assez fins, car le code scientifique a tendance à utiliser des fonctions assez longues, il faut donc descendre au niveau de la ligne de code. En outre, ils mettent assez mal en valeur les problèmes ;
- Parallel Studio Amplifier présente un meilleur mapping vers le code source, ainsi que des statistiques globales (bande passante mémoire utilisée) qui permettent d'estimer s'il est possible d'aller plus loin dans l'optimisation. Il lui manque certains compteurs hardware pour bien remplir son rôle ;
- Vtune lui propose ces compteurs, mais est peu aisé d'accès ;
- l'usage de Parallel Studio Inspector est jugé absolument indispensable, en particulier pour sa capacité à détecter les race conditions ;
- il reste important de bien connaître son architecture matérielle, ne serait-ce que pour savoir quand il faut arrêter l'optimisation car on a atteint ses limites ;
- de même que sur une architecture distribuée, il est important de bien découper son travail afin de distribuer intelligemment les données sur les nœuds, dans une architecture multi-cœurs, une structure des données en mémoire qui respecte le fonctionnement du cache est indispensable pour avoir une bonne scalabilité du parallélisme.
3-B. Parallélisation d'Autoplano▲
La société chambèrienne Kolor développe un logiciel, nommé Autoplano, permettant d'assembler des photos pour en obtenir des panoramas. En particulier, nous avons eu droit à une impressionnante démonstration d'une photo de Paris de 26 Gigapixels, obtenue en fusionnant 2346 photos prises le même jour. Ce genre d'application est gourmand en calcul, d'autant plus que le nombre de photos et leur taille augmente.
Leur logiciel a donc été adapté pour fonctionner autant que possible en parallèle, afin de tirer parti des processeurs actuels. Voici quelques retours d'expériences :
- tout d'abord, s'il existe dans les bibliothèques d'Intel une fonction faisant ce qu'on veut faire, utilisons-la, on ne fera généralement pas mieux ;
- le simple fait de recompiler le code avec le compilateur Intel a généré une amélioration de 22% des performances. Il semble qu'en particulier, en 64 bits, ce compilateur fasse un très bon travail d'optimisation (hélas, ce genre d'amélioration dépend de l'application, sur un de mes codes, il n'y avait eu aucune amélioration) ;
- à l'époque de la création du logiciel, OpenMP a été préféré à TBB, bien que ce dernier semble plus puissant, car il était difficile de relire le code écrit avec TBB qui cassait le flot de progression d'un algorithme. Une version plus récente de TBB avec les expressions lambdas ne devrait plus avoir ce problème ;
- la bibliothèque IPP peut travailler en mono-cœur, ou en multi-cœurs. Comme l'aspect multi-cœurs était déjà géré à un niveau supérieur avec OpenMp, il a été jugé préférable de travailler avec IPP configuré en mono-cœur, afin de mieux contrôler ce qui se passe.
4. Conclusions▲
La situation est assez claire : les techniques de parallélisation, qui jusqu'à peu étaient uniquement utilisées dans le cadre des gros centres de calcul, vont devoir faire partie de la boîte à outils de tout développeur dans un futur proche.
Dans ce cadre, Intel qui a une bonne expérience du monde HPC continue à travailler sur des outils et bibliothèques pour faciliter cette tâche. Il n'est pas seul et la dernière version de Microsoft Visual Studio a clairement placé le développement parallèle dans ses nouveautés majeures.
On se retrouve actuellement devant une pléthore de bibliothèques et l'on peut légitimement se demander lesquelles utiliser. Voici le point de vue de James Reinders sur le sujet :
Que choisir ? Tout d'abord, si l'on est dans un des modes de fonctionnement pour lequel une bibliothèque de parallélisation orientée données permet d'écrire du code où la parallélisation est implicitement gérée, comme par exemple PLinq, Ct, Eigen... il serait dommage de s'en priver.
Ensuite, pour ce qui est de la manipulation explicite de tâches, les bibliothèques pullulent. La question est que choisir. Je n'ai pas une expérience pratique dans ce domaine, aussi ce que je vais dire tient plus du ressenti que de la connaissance. Une solution comme Cilk me semble trop restreinte pour pouvoir être vraiment utilisée. OpenMP a un certain historique derrière elle, mais son modèle à base de pragmas à ajouter au code me laisse dubitatif. J'hésiterais à l'utiliser sur un nouveau projet. TBB et PPL couvrent clairement le même domaine et sont pleinement concurrentes. TBB est plus mature, plus complète et portable. PPL est fournie de base avec le compilateur dominant du marché, elle a donc des chances de se répandre plus rapidement.
Globalement, nous sommes encore aux débuts de la démocratisation de la parallélisation et nous assistons à un véritable foisonnement de solutions. Mais on ne peut généralement pas se permettre d'attendre que le marché se stabilise, car c'est maintenant que le parallélisme est une opportunité pour se différencier face à la concurrence.
L'intérêt du parallélisme pour des applications de calcul ou encore pour du multimédia et des jeux ne fait aucun doute. C'est d'ailleurs dans ces domaines qu'il est aujourd'hui bien implanté, comme le prouvent entre autres les présentations qui nous ont été faites. Mais on peut se poser la question de sa pertinence dans d'autres domaines. Quand je navigue sur le Web, ce n'est pas mon processeur qui fait que j'attends, c'est la bande passante de mon réseau. Et quand j'écris le texte de cet article, je n'attends tout simplement pas. Alors, pourquoi paralléliser ?
Dans ces domaines, l'opportunité apportée par le parallélisme ne sera pas vraiment de faire fonctionner plus vite les applications d'aujourd'hui, mais de trouver de nouvelles fonctionnalités, actuellement impossibles à mettre en œuvre car trop coûteuses, mais que l'on pourra donner demain à des cœurs oisifs. Reste à inventer ces nouveaux concepts...
Merci à jacques_jean pour la relecture très détaillée qu'il a effectuée de cet article.