



1. Introduction▲
Le C++ fournit la notion d'héritage multiple, c'est-à-dire la possibilité pour une classe d'avoir non pas une, mais plusieurs classes de base. Cette fonctionnalité est assez controversée, souvent considérée comme trop complexe et peu utile. Beaucoup de langages ayant leurs origines dans le C++ ont décidé de n'en permettre qu'une version limitée : l'héritage multiple d'interfaces. Ayant dû travailler avec un de ces langages, le C#, j'ai pu constater en pratique combien l'héritage multiple me manquait et en quoi son absence entraînait la duplication de code.
C'est cette expérience que je souhaite partager ici, ainsi que quelques informations sur la manière dont on peut mettre en œuvre l'héritage multiple en C++.
2. Héritage simple▲
Le but de l'héritage est double : permettre à une classe dérivée d'accéder à une implémentation définie dans la classe de base, et permettre de définir une interface commune par laquelle plusieurs classes vont pouvoir être manipulées indifféremment.
On dit que l'héritage est simple quand il permet à une classe de dériver d'une classe et d'une seule. Cela peut sembler une limitation arbitraire et ça l'est. Il y a de nombreux cas où le design demanderait que l'on hérite de plusieurs classes. Le problème est que techniquement, un tel héritage est significativement plus compliqué à mettre en œuvre. Il peut être aussi plus complexe à utiliser pour le développeur. Ces deux points conjugués font que de nombreux langages orientés objet ont décidé de ne pas l'autoriser.
3. Une version bridée : l'héritage d'interfaces▲
La plupart des langages ne fournissant pas d'héritage multiple en proposent néanmoins une version limitée, nommée héritage d'interfaces. C'est-à-dire qu'en plus de définir des classes, il est possible dans ces langages de définir des interfaces : des classes n'ayant pas de données membres et n'ayant que des fonctions virtuelles pures (1). Une classe peut alors hériter d'une classe de base unique et d'un nombre quelconque d'interfaces.
Comme une interface ne définit aucune implémentation, hériter d'une interface ne permet donc de réaliser qu'un seul des deux objectifs de l'héritage : manipuler des classes différentes par l'intermédiaire de leur interface, mais pas de bénéficier de l'implémentation d'une classe de base.
Par rapport à l'héritage multiple, cette solution est plus simple à comprendre et à implémenter (même si son implémentation demande quand même pas mal d'efforts et reste relativement coûteuse à l'exécution). Elle est aussi moins puissante. Si ce manque de puissance n'était visible que dans des cas rares, on pourrait s'en accommoder, mais il y a au moins trois cas pour lesquels on se heurte avec désagrément à ces limitations :
- une interface ne permet pas de mettre en place des vérifications liées à la programmation par contrat ;
- hériter de l'implémentation peut être utile ;
- l'héritage multiple permet aussi de définir des types utilisant des politiques et dont l'interface varie.
3-A. Programmation par contrat▲
Dans la programmation par contrat, l'utilisateur d'une fonction a signé un contrat avec l'implémenteur de cette fonction. Ce contrat se décrit généralement sous la forme de préconditions qui doivent être vraies quand la fonction est appelée, et de postconditions qui doivent être vraies une fois que la fonction retourne.
On vérifie généralement ces conditions par des instructions du type "assert", qui lèvent une erreur à l'exécution si une condition n'est pas vérifiée et qui sont désactivables dans les cas où l'on a besoin de performances maximales.
Quand on parle programmation par contrat et héritage, le respect du LSP (Liskov Substitution Principle) peut s'énoncer ainsi :
- dans une classe dérivée, on a uniquement le droit d'avoir des préconditions moins strictes que dans la classe de base ;
- dans une classe dérivée, on a uniquement le droit d'avoir des postconditions plus strictes que dans la classe de base.
Dit autrement, la classe dérivée doit au moins fournir les mêmes services que la classe de base. Souvent, on peut se contenter, en termes de validation, d'une forme réduite de ces règles (mais le mécanisme que je vais présenter permet d'implémenter les règles dans leur forme générique, c'est juste plus long à expliquer) : une classe dérivée doit avoir des fonctions avec les mêmes préconditions et postconditions que dans la classe de base.
Comment concrètement mettre en œuvre la vérification de ces conditions ? Il faut les vérifier à chaque appel de la fonction par le client, et ce quelle que soit la manière dont une classe dérivée est implémentée. On voit tout de suite qu'écrire du code ainsi pose problème :
class CompteEnBanque
{
public:
int solde();
virtual void retirer(int montant)
{
// préconditions
assert(montant > 0);
assert(montant > solde());
int monAncienSolde = solde();
// Réaliser le transfert
// postconditions
assert(solde() == monAncienSolde - montant);
}
};En effet, une personne qui dériverait de la classe CompteEnBanque aurait tout loisir de ne pas respecter le contrat, puisqu'il redéfinit la fonction "retirer". Une autre façon de voir les choses est de dire qu'actuellement, la fonction "retirer" fait deux choses : elle assure l'interface avec l'utilisateur de la classe (et donc le respect du contrat) et elle sert de point d'entrée pour une personne dérivant de cette même classe. Une fonction qui fait deux choses en fait une de trop.
La solution classique, parfois nommée NVI (non virtual interface) est donc la suivante :
class CompteEnBanque
{
public:
int solde();
void retirer(int montant)
{
// préconditions
assert(montant > 0);
assert(montant > solde());
int monAncienSolde = solde();
doRetirer(montant);
// postconditions
assert(solde() == monAncienSolde - montant);
}
private:
virtual void doRetirer(int montant) = 0;
};Comme la fonction publique "retirer" est non virtuelle, tout utilisateur manipulant un compte en banque par cette classe de base va passer par ce code et donc voir son contrat respecté, quelle que soit la manière dont on a pu dériver de cette classe.
Dit autrement, toute fonction virtuelle devrait être privée (ou protégée, si on estime que les classes dérivées ont de bonnes raisons d'utiliser l'implémentation de la classe de base) et toute fonction publique devrait vérifier les conditions.
Or, dans les langages présentant ce concept (en C# par exemple), toutes les fonctions définissant une interface sont obligatoirement virtuelles et publiques. Elles ne peuvent pas non plus contenir de code de validation (ou d'instrumentation, log ou mesure de performances, par exemple). Et même, il est parfois impossible avec ces langages d'avoir une fonction virtuelle et privée, c'est-à-dire que contrairement au C++, les droits d'accès ne servent pas uniquement à indiquer qui aura le droit d'appeler une fonction, mais aussi qui aura de droit de la redéfinir. Ces langages ne se prêtent donc pas nativement à la vérification de conditions pour la programmation par contrat.
Il existe néanmoins depuis peu un mécanisme facilitant la programmation par contrat en C#, mais il a lieu en dehors du langage et passe par des outils modifiant le comportement du compilateur. Pour les aspects de pré et post conditions liés aux interfaces ou aux fonctions virtuelles, il consiste à écrire des instructions qui vont demander au compilateur d'ajouter du code dans toutes les classes implémentant l'interface.
3-B. Héritage d'implémentation▲
Un autre cas où l'héritage multiple non bridé est souvent utile est quand on veut s'insérer dans une hiérarchie existante, tout en apportant sa propre structure complémentaire. Par exemple, imaginons que nous développions une interface graphique permettant d'afficher un tableau de bord de gestion.
Ce tableau est composé d'éléments à placer dans des cases. Chaque élément possède des points communs. Par exemple, il est associé à une boîte de propriétés qui permet de le configurer, il a un point d'accès à un moteur de calculs d'où il peut tirer ses données à afficher et est relié à un gestionnaire d'undo/redo.
Mais chaque élément est aussi un élément graphique, au sens de la bibliothèque d'IHM qui va être utilisée pour gérer le projet et cette bibliothèque, fournie par une tierce partie, n'est bien entendu pas modifiable. Selon la nature de ce qu'on veut afficher, il peut être judicieux de dériver d'un composant affichant une liste d'objets, d'une grille, d'un composant affichant des camemberts...
Avec de l'héritage multiple, le design ressemblerait à celui-ci :
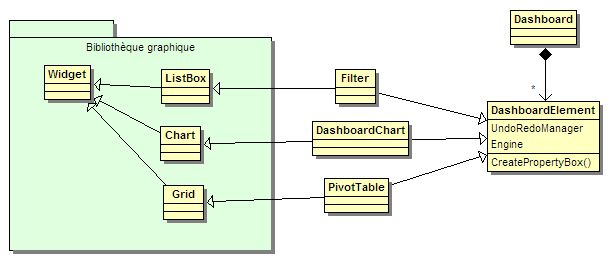
Comment approcher cette situation avec simplement un héritage d'interfaces ? Si on avait la possibilité de modifier le code de la bibliothèque, on pourrait réviser totalement la hiérarchie de manière à ce que les classes comme ListBox dérivent de DashBoardElement, mais ce serait un peu bancal, toutes les listes déroulantes n'ayant pas pour vocation d'être un élément de tableau de bord.
On pourrait faire en sorte que DashBoardElement ne soit qu'une interface. Le problème est alors que l'on doit dans chaque classe implémentant cette interface dupliquer le code lié à celle-ci, généralement identique d'une classe à l'autre (on peut noter que dans le design initial, aucune des fonctions de DashBoardElement n'était virtuelle). Si ce code est assez gros, on peut en déléguer l'implémentation à une autre classe, mais on doit quand même dupliquer l'appel à cette implémentation séparée. C'est ce que recommandent les gens qui disent que l'héritage multiple peut avantageusement être remplacé par de la composition :
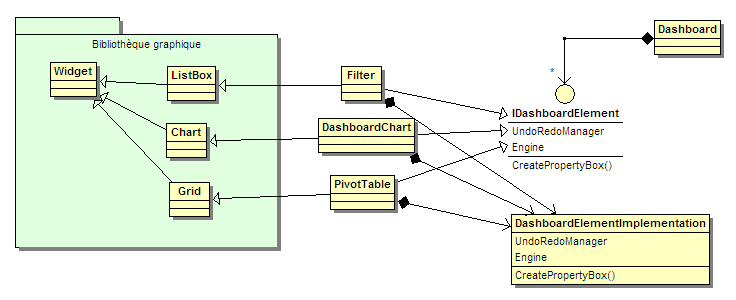
On va quand même dans chaque classe implémenter des fonctions qui ne font que transmettre à la classe d'implémentation :
void PivotTable::SetEngine(Engine e)
{
myImplementation.SetEngine();
}Déjà que cette écriture est fastidieuse, et donc source de bogues d'inattention, elle présente un autre problème : à chaque fois qu'il faut modifier l'interface, il faut reprendre toutes les classes qui implémentent cette interface afin d'y répercuter la modification, alors que dans le design initial, seules les classes directement concernées par la modification devaient en tenir compte.
On a donc au final un design plus complexe, avec des recopies de code en grand nombre et une moindre souplesse.
3-C. Mise en place de politiques▲
Imaginons un type que l'on veut rendre paramétrable de façon à ce qu'il puisse répondre à divers besoins. Si ce paramétrage est constant et peut être connu à la compilation, l'idéal pour faire cela en C++ est d'utiliser les templates. Prenons par exemple la définition d'une classe d'arbre binaire trié configurable.
Cet arbre peut être configuré de multiples manières : comment les nœuds sont comparés entre eux, comment l'arbre est rééquilibré, comment sont alloués les nœuds et bien entendu le type de données stockées dans l'arbre. Cette classe pourrait être définie ainsi :
template <class T, class Comparator, template <class> class AllocationPolicy, class BalancingPolicy> class Tree;Et l'utilisateur pourrait instancier selon ses besoins un :
Tree<string, less<string>, CreateWithNew, RedBlack> monArbre;
Tree<NobelPrice, SortByYearAndName, CreateInMemoryPool, AVL> monAutreArbre;On peut a priori implémenter cette classe sans héritage, jusqu'à ce qu'une politique ait besoin de fonctions supplémentaires pour être utilisée. Par exemple, imaginons que dans la politique d'allocation par pool mémoire, on veuille pouvoir indiquer à l'arbre dans quel pool la mémoire doit être allouée :
template <class Node> class CreateInMemoryPool
{
public:
Node* Create();
void SetMemoryPool(MemoryPool<Node> *pool);
// ...
};On veut donc sur un arbre implémenté à base de CreateInMemoryPool, et sur ce type d'arbre seulement, pouvoir appeler la fonction SetMemoryPool, fonction dont on ne connaissait même pas l'existence au moment où l'on a défini la classe Tree. Tree doit offrir à son utilisateur une interface qui va dépendre des politiques utilisées.
La méthode classique pour y parvenir est de faire hériter la classe Tree de ses politiques (noter le pluriel : une classe a plusieurs politiques) et comme les classes de politique sont par définition des classes avec du code dedans et avec éventuellement des données membres, on a besoin d'un véritable héritage multiple, pas d'un héritage d'interfaces :
template <
class T,
class Comparator,
template <class> class AllocationPolicy,
class BalancingPolicy>
class Tree :
public Comparator,
public AllocationPolicy<Node<T>>,
public BalancingPolicy
{
// ...
};4. Héritage multiple▲
J'espère vous avoir convaincu dans les chapitres précédents de l'intérêt de l'héritage multiple. Ce chapitre revient maintenant sur certains points de détail à maîtriser pour utiliser correctement ce concept. Si l'implémentation peut être assez complexe, l'utilisation de cette fonctionnalité n'est, dans la plupart des cas, pas très compliquée.
4-A. Appels ambigus▲
Comme on peut avoir plusieurs classes de base, elles peuvent entrer en conflit les unes avec les autres. Que se passe-t-il s'il y a ambiguïté entre deux fonctions ou données membres ?
class A
{
public:
void f();
};
class B
{
public:
void f();
};
class C : public A, public B
{
public:
void g() {f();} // ?
}Tout simplement, le compilateur refusera de compiler ce code ambigu et demandera à ce que l'appel soit qualifié : A::f() ou B::f(). À noter que si une fonction f est définie directement au niveau de C, c'est elle qui aura la priorité et il n'y aura pas d'ambiguïté.
4-B. Héritage en diamant▲
Il est interdit d'hériter directement plusieurs fois de la même classe de base.
class A;
class B : public A, public A {} // ErreurPar contre, on peut se retrouver à hériter plusieurs fois indirectement de la même classe de base. Si cette classe de base commune n'a pas de données membres et n'a pas de fonction virtuelle qui aurait été redéfinie différemment dans les classes dérivées, il n'y a pas vraiment de questions à se poser. Si elle en a, on peut vouloir deux situations différentes :
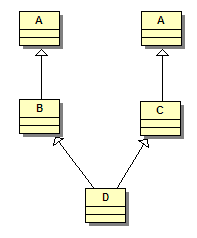
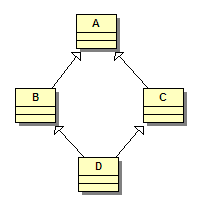
La seconde situation se nomme généralement héritage en diamant, à cause de la forme losange prise par le diagramme de classes. Par défaut, si on écrit le code suivant :
class A {};
class B : public A {};
class C : public A {};
class D : public B, public C {};On n'obtient pas un héritage en diamant, mais un héritage où la classe A (et ses données membres) se trouve dupliquée.
Pour obtenir un héritage en diamant, il faut utiliser l'héritage virtuel :
class A {};
class B : public virtual A {};
class C : public virtual A {};
class D : public B, public C {};On voit là poindre un premier problème : l'héritage en diamant devrait pouvoir être spécifié au niveau de D mais c'est en fait dès le niveau de B et C qu'il doit être indiqué. Un problème annexe existe : comment la partie A de l'objet va-t-elle être construite ?
En effet, en tant que sous-partie de B, elle devrait être construite selon les paramètres définis dans le constructeur de B et en tant que sous-partie de C, en fonction des paramètres définis dans le constructeur de C. Il y a, dès la construction, ambiguïté (qu'il n'y avait pas dans le cas précédant, où deux sous-parties A étaient construites).
Il a donc été décidé de ne choisir ni l'un ni l'autre, mais d'imposer au constructeur de D de spécifier directement comment la partie A de D sera construite. Tout appel au constructeur de A depuis B ou C sera ignoré lors de la création d'un D.
D::D() : A(10), B(42), C(12) {}4-C. Cast▲
En présence d'héritage multiple, on peut avoir quelques surprises quand on transtype (cast) des pointeurs sur objet. En effet, un cast est plus qu'une simple réinterprétation d'un pattern de bits, mais une véritable opération qui peut provoquer des décalages.
class A
{
public:
virtual ~A() {} // Pour dynamic_cast
int i;
};
class B
{
public:
virtual ~B() {} // Pour dynamic_cast
int j;
};
class C : public A, public B {int k;};
C c;
C* pc = &c;
B* pb = &c;
A* pa = &c;On pourrait croire dans le code précédent que pa, pb et pc ont la même valeur et pointent sur la même zone mémoire. C'est faux. Le pointeur pa pointe sur la sous-partie de c où est stocké i, pb pointe sur la sous-partie de C où est stocké j. Ces deux adresses sont différentes entre elles.
De même, le code exécuté quand on fait :
C* pc2 = dynamic_cast<C*>(pb);est assez complexe et va provoquer, grâce au RTTI, un décalage inverse de pointeur afin que pc2 pointe bien sur l'ensemble de l'objet de type C et non plus sur la sous-partie de C où est stocké j.
Par contre, si on fait :
B* pb2 = reinterpret_cast<B*>(&c);On empêche le compilateur de faire les décalages d'adresse nécessaires et pb2 va pointer n'importe où. Encore plus que dans le cas général, éviter à tout prix reinterpret_cast en présence d'héritage multiple.
5. Conclusion▲
On vient de voir que l'héritage multiple peut avoir son lot de complexités. Ces dernières sont de trois natures différentes :
- plus de travail à faire lors d'un cast de pointeur. Il s'agit là d'une complexité uniquement visible par une personne développant un compilateur C++, sauf si on commence à jouer avec reinterpret_cast, ce qu'on ne devrait de toute façon jamais faire dans ce genre de situation ;
- il peut y avoir des appels de fonction ambigus, mais ils sont détectés à la compilation et ne devraient pas poser de véritables problèmes pour être corrigés ;
- l'héritage en diamant apporte à lui seul toute une série de particularités supplémentaires.
L'héritage multiple n'en reste pas moins une technique très appréciable pour mettre en place une architecture propre. On peut décider de se limiter en C++ au sous-ensemble de l'héritage multiple qui reproduit les fonctionnalités fournies par les interfaces de C# ou Java. Un exemple classique est le cas où une hiérarchie d'interface est mise en parallèle d'une hiérarchie d'implémentation, chaque classe d'implémentation devant alors hériter d'une classe d'implémentation et hériter virtuellement de la classe d'interface correspondante, ce qu'on nomme parfois de l'héritage en treillis.
Mais on peut aussi aller plus loin et autoriser les classes de base à contenir d'autres éléments que des fonctions virtuelles pures. Ce qui est notable, c'est que dans les trois exemples cités où l'héritage multiple avec classes de base non creuses avait de l'intérêt, la problématique de l'héritage en diamant, la plus gênante, n'existait pas, on n'avait même pas à se poser la question.
Donc, même si on peut avoir peur des difficultés à maîtriser l'héritage multiple à partir du moment où une même classe de base intervient plusieurs fois, ce qui n'est pas forcément si courant en pratique et il serait dommage de se passer entièrement de la souplesse apportée par l'héritage multiple juste à cause de la crainte de se retrouver dans une situation d'héritage en diamant.
Merci beaucoup à jpoulson, ram-0000, _Max_, ClaudeLELOUP, Davidbrcz ainsi plus généralement aux contributeurs du forum pour leurs suggestions et corrections. Toutes les erreurs résiduelles sont de moi.